Self-hosted GitOps Pipeline: Komodo + Renovate
假如一台服务器上跑着十几二十个自托管服务:订阅记账、电子书库、照片备份、媒体服务器,外加一堆小工具,此时单纯靠手动维护,用不了多久就会变成一件头疼事。我们可以考虑把它们交给 Git 管理:
- 每个服务写成一个 Compose 文件、pin 到固定的镜像版本
- 由 Komodo 从仓库自动部署
- 由 Renovate 监测上游镜像、发现新版本后提 PR 升级
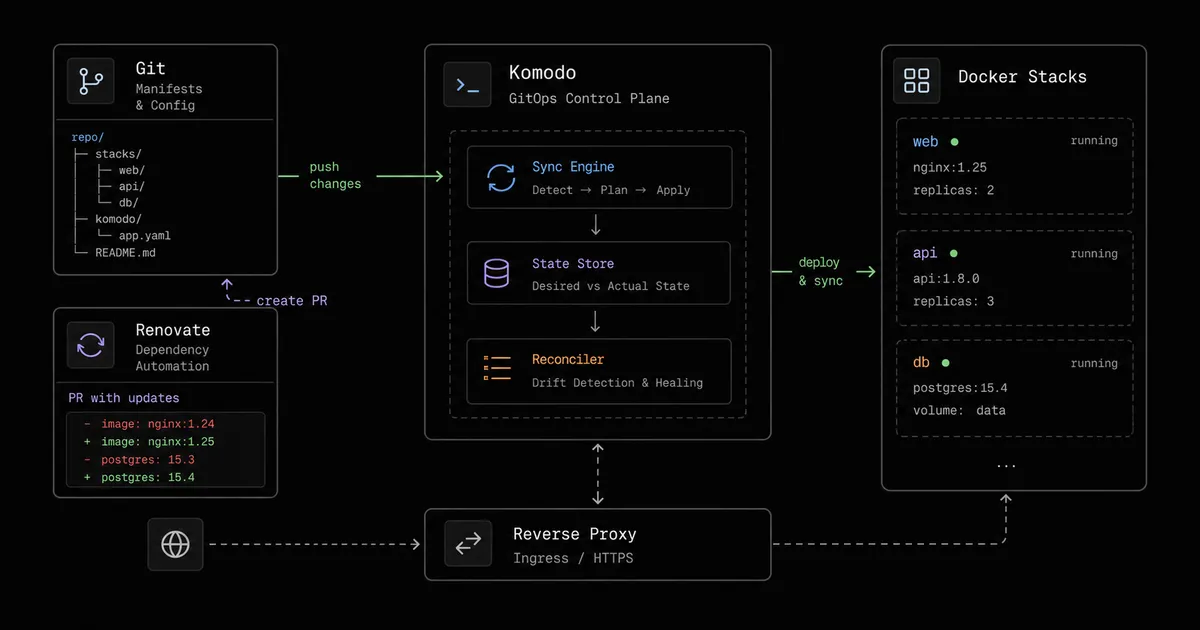
若是单靠手动管一台服务器,时间久了状态会散到四处。一个服务的真实配置同时存在于:SSH 进去敲过的命令、某个 docker-compose.yml 的当前版本、.env 里的密钥、挂载的配置文件、半年前临时改的一行参数。等到机器挂了要重建,或者只是想回忆当初为什么这么配,能依赖的只有记忆和零散的备份。
而对于镜像版本,为了快速部署好服务,往往会选择 image: app:latest,于是每次 docker compose pull 都可能拉到一个不一样的镜像,若是更新失败很难找到引发 breaking change 的小版本。而若是把版本 pin 到部署时的稳定版本,后续升级又得记着去官网翻 changelog,于是镜像一放就是两年,安全补丁和新功能也跟着一起落下。每次的操作都让系统的混乱度增加,越来越难以维护。
这源于服务器的真实状态没有一个单一、可信、带历史的来源。GitOps 正是一个好的解决方案,将 Git 仓库作为服务器状态的唯一事实来源,机器自动与其对齐。
GitOps:让 Git 成为唯一事实来源
GitOps 这个词最早来自 Kubernetes 社区,但它的思想跟编排引擎无关,落到一台跑 Docker 的服务器上同样成立。CNCF 旗下的 OpenGitOps 把它收敛成四条原则,逐条对到自托管场景上看会很清楚。
-
声明式。只需描述系统应该是什么样,怎么一步步达成交给工具去算。一个
compose.yaml就是声明:这个服务用哪个镜像、开哪个端口、挂哪些目录。「先 pull 再 stop 再 up」这些动作不用写,工具会自动执行。 -
有版本、不可变。期望状态存在一个能保留完整历史的地方,也就是 Git。每一次变更都是一条带作者和时间戳的 commit,想回到上周的状态,
git revert就够了。 -
自动拉取。有一个软件代理自动把期望状态从仓库取下来,不靠人手动
git pull再docker compose up。 -
持续对账。代理不断比对「仓库里写的」和「机器上跑的」,发现漂移就拉回来。
严格的 GitOps 工具(Flux、Argo CD)跑的是一个持续拉取加不断对账的循环,适合大规模 Kubernetes 集群。一台个人服务器用事件驱动就足够了:每次推送触发一次同步,省资源也好理解。Komodo 正好提供这种事件驱动的能力。
这样带来的好处很直接。每一次变更可追溯、可回滚;机器整个没了,一次 git clone 加上密钥和数据的备份就能重建;两个月后回头看某个奇怪的参数,git blame 直接指出是哪次提交,配套的 commit message 也写了为什么。
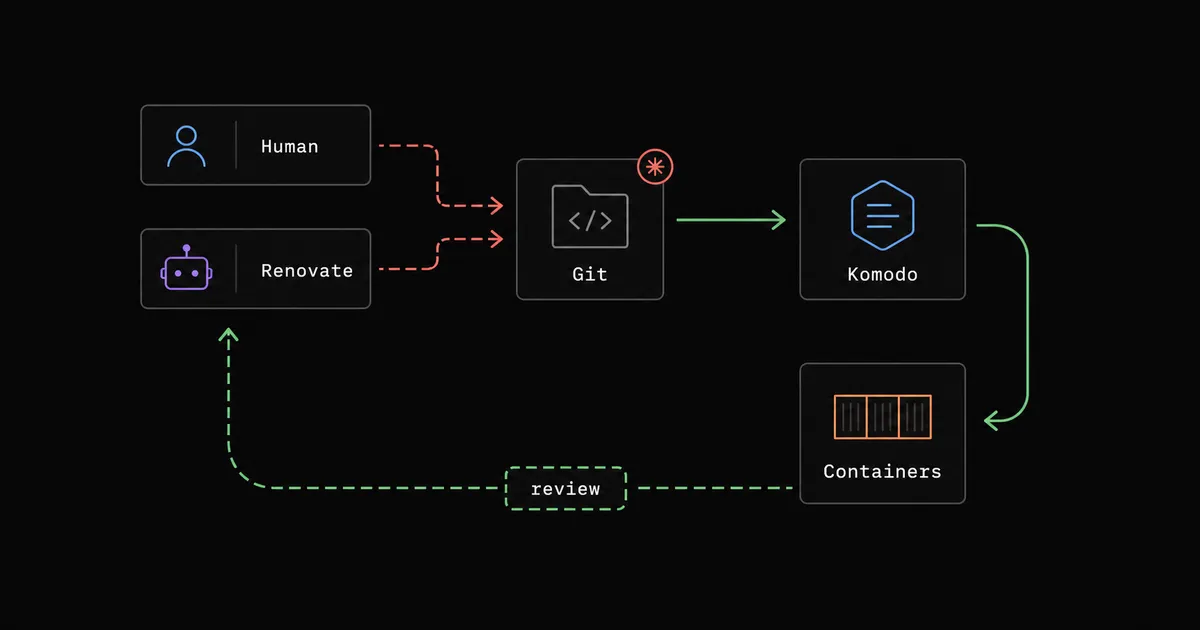
Komodo:Docker Compose 连接 Git 控制平面
Komodo 是一个开源的容器构建与部署平台,用来在一台或多台服务器上管理 Docker。很多人用过 Portainer 来管容器,Komodo 站在类似的位置上,提供 Web UI、API、告警和权限管理,把每个 Compose 项目当成一个叫 Stack 的资源来管理:查看状态、看日志、改配置、一键部署都在界面里完成。
它的部署模型分成两部分:
- Core 是大脑,跑 Web UI、API 和一个数据库(默认 MongoDB),存放所有资源定义、变量、用户和审计日志。
- Periphery 是手脚,是装在每台被纳管服务器上的一个轻量代理,Core 通过它在那台机器上执行真正的 Docker 命令。一个 Core 可以连任意多台跑着 Periphery 的服务器,所以同一套控制平面能横跨好几台机器统一管理。
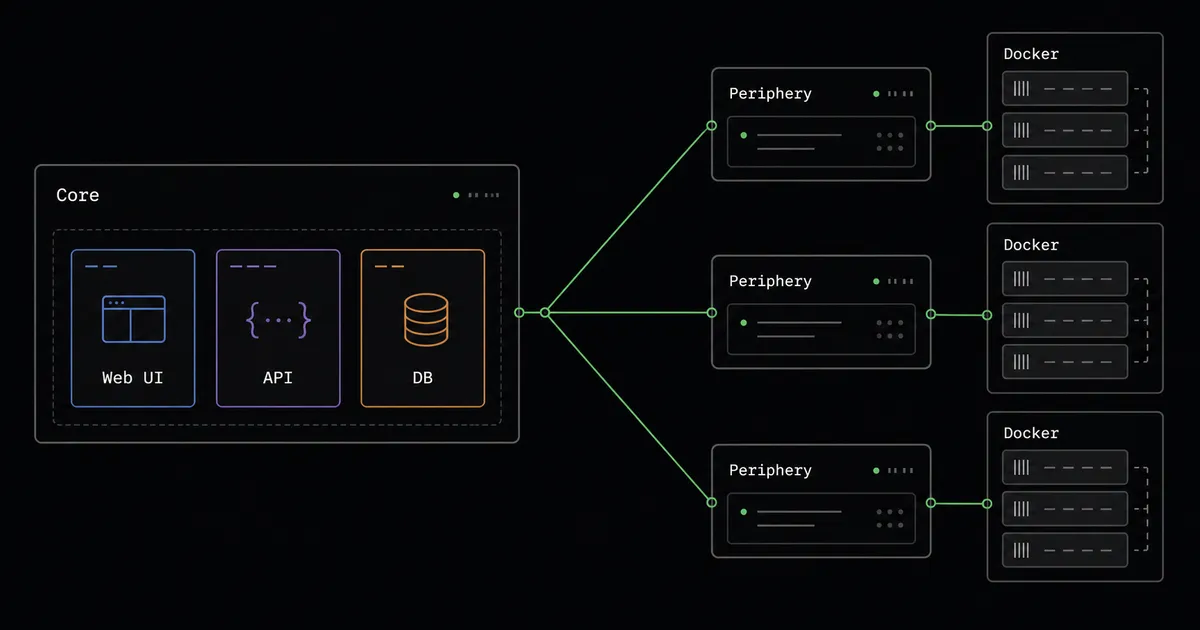
Core 是控制平面,Periphery 是真正在每台机器上动手的代理
Komodo 真正适合 GitOps 的地方,是这些资源本身可以用代码声明。它提供一种叫 Resource Sync 的资源:把所有 Stack 的定义写进一个 TOML 文件、提交进 Git,Komodo 读这个文件,把里面声明的资源在服务器上创建出来并保持一致。这意味着「有哪些服务、各自怎么配」这件事也通过 Git 来管理,跟代码一样有版本、有历史。
在 sync.toml 里,每个服务对应一个 [[stack]] 块:
[[stack]]name = "wallos"description = "https://wallos.example.com"deploy = falsetags = ["app"]
[stack.config]server = "server-a"linked_repo = "homelab-infra"run_directory = "stacks/wallos"file_paths = ["compose.yaml"]字段含义并不复杂。server 指定部署到哪台被 Komodo 纳管的服务器(也就是哪个 Periphery);linked_repo 指向一个在 Komodo UI 里配好的 Repo 资源,Git 账号、仓库地址、访问令牌这些实例相关的东西因此留在 Komodo 里,仓库这个文件里只出现一个名字,干净、可移植;run_directory 和 file_paths 指定去仓库的哪个子目录、读哪个 Compose 文件,deploy = false 则把部署这件事从 sync 里摘出去。
对应的 Compose 文件就是一份标准的 compose.yaml,若是需要脱离 Komodo,直接 docker compose up -d 就能跑,没有生态的锁定。Komodo 只是在外面包了一层声明、调度和可观测性。
services: wallos: container_name: wallos image: bellamy/wallos:4.9.5 ports: - "20000:80/tcp" environment: TZ: Asia/Shanghai volumes: - /srv/wallos/db:/var/www/html/db - /srv/wallos/logos:/var/www/html/images/uploads/logos restart: unless-stopped
networks: default: name: wallosKomodo 自身的安装是这套体系里唯一一处手动操作。它由 Core、Periphery 和一个数据库组成,没法部署自己,所以这部分按官方手册在主机上 docker compose up -d 拉起一次即可,之后所有业务服务都归 Git 管。同样的,也可以把 Komodo 自己的 Compose 和 .env 也以脱敏形式留一份在仓库里,作为版本记录和灾备依据。
整套基础设施声明放在一个 Git 仓库里,不按服务或机器拆成多个,在一个仓库内可以囊括所有服务的配置、一套 Renovate 规则、一条部署流水线,对于跨服务的改动,一个 commit 就可以完成。
homelab-infra/├── sync.toml # 所有 Stack、Procedure、Server 的声明├── renovate.json # Renovate 检测规则├── ports.md # 端口登记表├── stacks/ # 一个服务一个目录,目录名就是 Stack 名│ ├── wallos/│ │ └── compose.yaml│ └── immich/│ ├── compose.yaml│ └── config.example.yaml # 带密钥的配置,只留脱敏样板└── komodo/ # 控制平面自身,同样以脱敏样板留档 ├── compose.yaml └── compose.env.examplestacks/下一个服务一个目录,目录名跟 Stack 名对齐,sync.toml里的run_directory = "stacks/wallos"正是把声明指到这个目录;加服务就是新建一个目录、放进compose.yaml,再到sync.toml补一个[[stack]]指过去。- 服务运行在哪台机器由每个 Stack 的
server字段决定,所以同一个仓库天然能管多台机器,加机器也只是在sync.toml里多一个[[server]]块。
Komodo 会把这个仓库 clone 到主机的工作目录,所以仓库里只存放声明,运行态的东西则留在仓库外:
- 应用数据在
/srv/<service>/ - 真实密钥在 Komodo 的加密变量库、部署那一刻才落成一个 git-ignored 的
.env - 控制平面自己的资源定义和账号在 Komodo 的数据库里。
一次 git push 的完整历程
当发起一次推送,从 Git 走到容器的过程中,入口是 Git 仓库上的一个 push webhook。Komodo 的 webhook URL 有固定结构:
https://<HOST>/listener/<认证类型>/<资源类型>/<id 或名字>/<执行项>认证类型是 github 等,对应平台来源;资源类型则可以是 stack、sync、procedure 等;执行项随资源类型而定。配置 webhook 时把 content-type 设为 application/json,并填上在 Komodo 里设好的 WEBHOOK_SECRET,Komodo 在收到后会校验 GitHub 带来的 X-Hub-Signature-256 签名,确认这次调用确实来自该仓库,并挡掉伪造请求。
最朴素的做法是让这个 webhook 直接指向 Resource Sync,推送即同步即部署。但服务一多,可能会暴露两个问题:
- 双重部署竞争。既让 Resource Sync 在推送时部署,又另设一个部署动作,两者同时开跑,会去抢同一个 Stack 的部署锁,Komodo 可能会触发
Resource is busy; - 新服务首推漏部署:新加的 Stack 在它的定义还没被 sync 创建出来时就被部署动作轮到,于是第一次推送起不来,得手动去 UI 点一下。
合适的做法是把「同步定义」和「执行部署」拆成有先后的两步,交由 Komodo 的 Procedure 来编排。Procedure 把多个执行项组织成若干 Stage,Stage 之间顺序执行,同一个 Stage 内的执行项并行跑,前一个 Stage 全部完成才进下一个。据此搭一个 Redeploy On Push Procedure:
Renovate / 用户 合并 PR 到 main │ ▼Git push webhook ──► Procedure "Redeploy On Push" │ ├─ Stage 1: RunSync "homelab" │ 读 sync.toml,协调资源定义(创建 / 更新 Stack) ▼ └─ Stage 2: BatchDeployStackIfChanged "*" 只部署 compose 内容真正变过的 Stack- Stage 1 跑
RunSync,让 Komodo 重新读sync.toml,把里面声明的 Stack 定义对齐到最新 commit; - Stage 2 跑
BatchDeployStackIfChanged,这是 Komodo 的批量执行项,用通配符匹配资源名,只对 compose 内容相比上次有变化的 Stack 触发部署。
[[procedure]]name = "Redeploy On Push"
[procedure.config]webhook_enabled = true
[[procedure.config.stage]]name = "Sync resource definitions"executions = [ { execution.type = "RunSync", execution.params.sync = "homelab" },]
[[procedure.config.stage]]name = "Redeploy changed stacks"executions = [ { execution.type = "BatchDeployStackIfChanged", execution.params.pattern = "*" },]Renovate 把版本升级变成可审阅的 PR
Renovate 是一个自动更新依赖的机器人。它定时扫描仓库,对每一处声明的依赖去上游查是否有新版本,开 PR 把版本号改到最新,并会附上 changelog。
引入 Renovate 有两种方式:
- Mend 托管的 GitHub App:在 Marketplace 装上、授权给目标仓库,Mend 自己的基础设施按大约每小时一次的节奏临时 clone 仓库、扫描、提 PR,跑完不留存代码,不用可以修改仓库里的 CI。
- 自托管:把 Renovate 当 npm 包、Docker 镜像,或者一个定时跑的 GitHub Action 自己运行,控制更细。
整套体系有一条隐含前提,镜像 tag 需要 pin 到固定版本,Renovate 才能去实现检测。此外,固定版本也可以让部署可复现,整套体系更稳定。
数据库和缓存则依照另一套规则,锁到大版本线:
image: pgvector/pgvector:pg17image: redis:8一个好用的判断标准是看升级要不要人介入数据迁移,需要的话就就锁大版本线,若只是无痛补丁,则锁精确版本让 Renovate 自由提 PR。
一个最小可用的 Renovate 配置很短:
{ "$schema": "https://docs.renovatebot.com/renovate-schema.json", "extends": ["config:recommended", ":dependencyDashboard", ":semanticCommits"], "timezone": "Asia/Shanghai", "labels": ["dependencies"], "prConcurrentLimit": 0, "prHourlyLimit": 0}config:recommended是官方推荐基线,把大部分合理默认值打开。:dependencyDashboard会在仓库里自动维护一个 Dependency Dashboard issue,把所有待升级、被忽略、有冲突的项汇总在一个看板上,一眼看清全局,也能在上面手动勾选触发某个升级。:semanticCommits规定 Renovate 的 commit 和 PR 与语义化提交风格统一,整体更规范。prConcurrentLimit和prHourlyLimit则是限流阀门。Renovate 默认会限制同时打开的 PR 数和每小时新建的 PR 数。当服务数量比较多时,这个限制反而拖慢升级的节奏,此时可以把两个值都设为 0。
随着服务数的增加,为减少 PR 噪音,可以通过 packageRules 进行分组和调度。比如把同一个 Stack 目录下的多个镜像合并成一个 PR,或者只在每周固定时间开 PR:
"packageRules": [ { "matchManagers": ["docker-compose"], "matchFileNames": ["stacks/immich/**"], "groupName": "immich", "schedule": ["* 0-6 * * 1"] }]分组让一组关联镜像(比如 immich 的 server 加 machine-learning)一起升、一起审、一起部署,避免它们版本错配;调度把 PR 收拢到固定的时间窗口。两者配合,PR 噪音基本能压到可接受的程度。
至于自动合并,Renovate 支持给某些低风险更新(比如 digest、pin、补丁)开 automerge。而在自托管个人服务上,review 一行版本号的 bump 成本很低,却能让每次变更都心里有数,所以多数人会把审核留给自己。
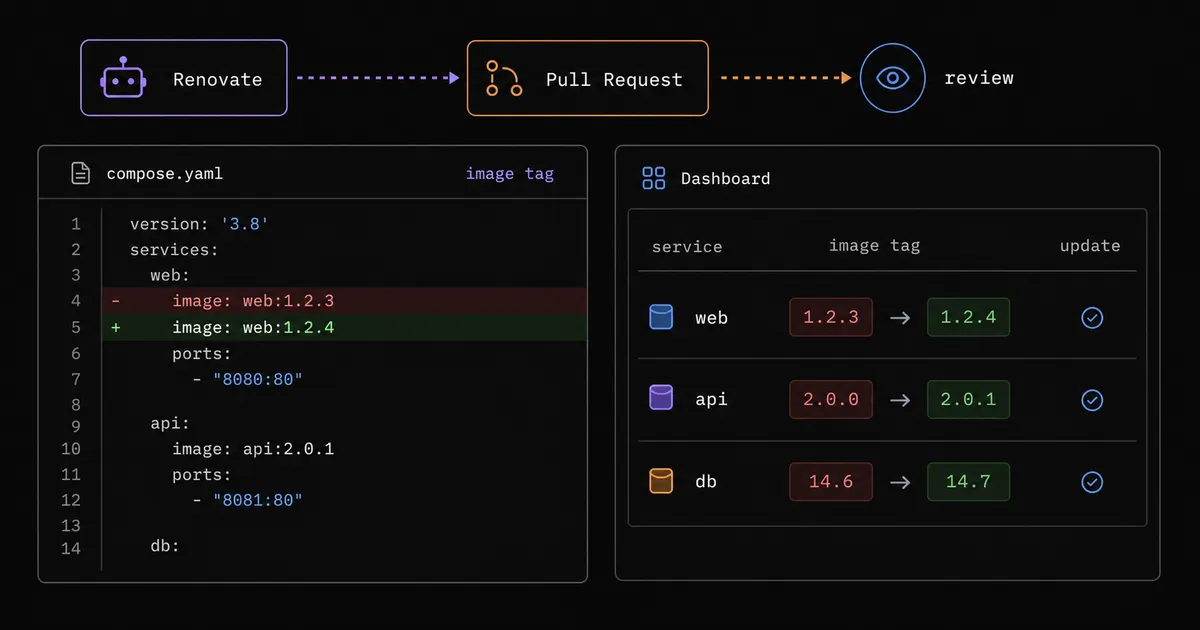
整套升级流程始于 Renovate 创建 PR 更新 image tag,在审核合并后,push webhook 触发 Redeploy On Push Procedure,Komodo 检测到 compose 发生变化,便会重新部署对应 Stack。
理解 Compose 的环境变量
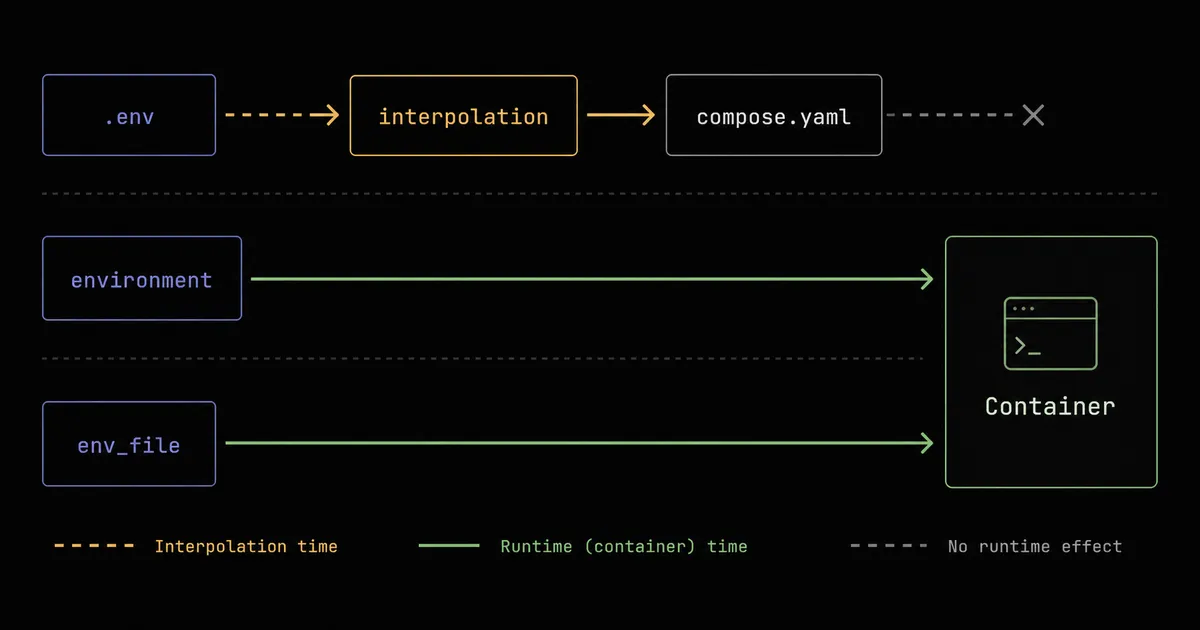
Docker Compose 的环境变量机制是密钥注入的基础,${VAR} 这个写法在 Compose 里身兼两职:
-
第一职是插值。Compose 在解析
compose.yaml这个文件时,会把文件里出现的${VAR}就地替换成具体值。值从两个地方取:执行docker compose时的 shell 环境变量,以及项目目录下一个名叫.env的文件。两者都有同名变量时,shell 环境变量优先。这一步发生在容器还没创建之前,只是简单的文本替换。 -
第二职是给容器设环境变量,靠
environment:和env_file:两个字段:services:app:environment: # 直接写进容器进程的环境变量- TZ=Asia/Shanghai- DB_HOST=postgres- DB_PASS=${DB_PASS} # 这里的 ${DB_PASS} 是「插值」,先被替换,再设进容器env_file:- ./app.env # 从这个文件逐行读 KEY=VAL,设进容器
分界线在这里:项目目录那个 .env 文件只为「插值」服务,它自己不会自动进容器。也就是说,在 .env 里写了 FOO=bar,容器里默认看不到 FOO,除非在 environment: 里显式写 FOO=${FOO},或者把它列进 env_file:。env_file 指向的文件则相反,里面的每一行都会成为容器的环境变量。
有几点需要注意,比如:
environment里同名变量会覆盖env_file里的;.env里的KEY=VAL等号两边不能有空格;- 要在 Compose 的值里写一个字面的
$,得转义成$$,比如健康检查里用 shell 变量:这里healthcheck:test: ["CMD-SHELL", "pg_isready -U $$POSTGRES_USER -d $$POSTGRES_DB"]$$POSTGRES_USER经 Compose 转义后,传给容器内 shell 的是$POSTGRES_USER,交给容器内 shell 在运行时展开,绕开 Compose 的提前插值。
密钥:仓库里只留占位符
既然要把配置放进 Git,密钥就一个都不能进。守住这条线靠两套机制,都建立在 .env 插值这个入口上。
第一套处理环境变量型的密钥(数据库密码、API key)。Compose 里只写占位:
environment: POSTGRES_DSN: "postgres://app:${APP_DB_PASSWORD}@postgres:5432/app"真实值定义成 Komodo UI 里的 Variables & Secrets,再在 sync.toml 对应 Stack 的 environment 字段里做映射:
environment = """APP_DB_PASSWORD=[[APP_DB_PASSWORD]]APP_REDIS_PASSWORD=[[APP_REDIS_PASSWORD]]"""部署时,Komodo 把 [[ ]] 里的变量名解析成真实值,写进该 Stack run directory 下一个 git-ignored 的 .env 文件,接着 docker compose 自然读这个同目录的 .env 完成 ${VAR} 插值。整条链路下来,Git 里始终只有 ${VAR} 占位和 [[VAR]] 映射,真实密钥只活在 Komodo 的加密变量库和部署那一刻生成的 .env 里,落盘那份还在仓库克隆之外。
非密钥的配置(时区、PUID/PGID、功能开关)就直接写在 compose 的 environment: 里,提交进 Git,让服务自包含、好读。区分标准很简单:泄露了会出事的进 Komodo 变量,不会的进 compose。
第二套机制处理整份带密钥的配置文件,比如某些应用要的一个 config.yaml,里面密钥和普通配置混在一起。这种文件的真实版本放在主机的数据目录里,bind 挂进容器,跟着数据一起备份,本体留在 Git 之外;仓库里只提交一份把密钥抹掉的 config.example.yaml 当参考。还有个 Docker 小陷阱:bind 挂载单个文件时,这个文件必须在容器启动前就存在于主机上,否则 Docker 会好心地创建一个同名目录顶上去,应用一读就报错。
控制平面自己的密钥(数据库密码、首个管理员密码、webhook secret)是这套规则的唯一例外。Komodo 正是提供变量库 UI 的那个东西,自己的密钥没处安放,所以留在主机上它自己的环境文件里,git-ignored,同样以脱敏的 .example 形式在仓库里留一份结构参考。
几条约定:端口、网络、数据落盘
GitOps 给了机制,真正让几十个服务长期不乱的是一组人定的约定。下面这几条,每一条都对应过一个真实的坑。
端口顺序分配,有唯一登记表。 给每个对外服务的 host 端口定一个起始基数,比如从 20000 开始按 1 递增,每个发布到公网的服务占一个号,全部登记在仓库里一张端口表(一个 markdown 文件就够)。加服务时取下一个空号、在同一个 commit 里登记。只在网络内部通信的容器(数据库、缓存、搜索引擎)不发布 host 端口,因此不占号。这张表是端口分配的唯一事实来源,新服务该用哪个号、哪些号还空着,看一眼就知道,端口冲突这种低级故障基本绝迹。
数据用绝对路径 bind 到一个固定根目录。 这条约定背后是 Komodo 的工作方式:它会把仓库 clone 到主机上自己的工作目录里,每次重新部署都可能重新 clone。数据要是放在相对路径或命名卷里,就有跟着 clone 一起被刷掉的风险。所以持久数据一律 bind 到仓库克隆之外的一个固定根目录,比如 /srv/<service>/,用绝对路径:
volumes: - /srv/wallos/db:/var/www/html/db - /srv/wallos/logos:/var/www/html/images/uploads/logos这样数据独立于仓库克隆而存在,重新 clone、重新部署都不动它。备份也因此简单:备份 /srv 就备份了全部应用数据。命名卷只在镜像对 bind 挂载权限特别挑剔、或者那份数据纯属缓存可丢时才用,因为命名卷藏在 Docker 自己的目录里,更难备份,一个 docker compose down -v 还可能误删。
每个 Stack 显式命名默认网络。
networks: default: name: <stack>漏掉这一段,Compose 会按项目名生成一个 <project>_default 网络,名字带前缀、不可控。显式命名后,网络名稳定、可预期,将来要跨 Stack 互联(比如让一个服务用固定 IP 去寻址另一个)时也好对接。
镜像归属跟着各自的用户走。 不同镜像跑的用户不一样:LinuxServer 系的镜像认 PUID/PGID 环境变量,有的应用镜像以 www-data(uid 82)跑,Postgres 数据目录归 uid 999。让宿主上的数据目录属主跟随每个镜像自己的用户即可,强行压一个全局 UID 反而会和镜像打架。迁移数据时用 cp -a 保留属主和权限,Postgres 的数据目录尤其要是 999:999 且权限 700,否则它会直接拒绝启动。
迁移:把手工部署的老服务搬进来
这套体系很少是一夜建成的,多数人是把原先用 docker compose 手工部署在 /opt/<service>/ 之类目录里的服务,一个个搬进来的。
迁移前先把现状摸清楚:看老服务的 compose、镜像和 tag、发布的端口、用的是命名卷还是 bind 挂载、有哪些环境变量、密钥藏在哪。然后定 pin(应用精确版本、数据库大版本线),确认 pin 的版本就是当前在跑的版本,再认领一个端口,写好仓库里的 compose.yaml、sync.toml 条目和端口登记。
这里的顺序不能反:推送会自动触发部署,所以数据和密钥必须在推送之前就准备好。 正确的切换顺序是先停老服务,把数据 cp -a 到新的 /srv 目录,在 Komodo 里建好对应的 Variables,最后才推送让它部署。顺序反了,新容器会在一个空数据目录上起来,轻则报错,重则初始化出一份新数据盖掉旧的。
切换的核心动作大致是:
# 停旧服务,注意不要带 -v,命名卷要留着拷cd /opt/<service> && docker compose down
# 把每个卷拷到 /srv 的 bind 目录,保留属主和权限# 让 cp -a 自己创建叶子目录,不要先 mkdir,否则属主会变成 rootmkdir -p /srv/<service>cp -a /var/lib/docker/volumes/<volume>/_data /srv/<service>/<dir>
# 核对权限:Postgres 数据目录必须 999:999、700stat -c '%n %U:%G %a' /srv/<service>/*下面几条是搬十几个服务攒下来的、最容易翻车的地方。
有些密钥藏在数据目录里,不在环境变量里。 一些应用把自己的加密密钥写在数据目录的某个文件里:工作流工具的加密 key、聊天应用的 secret key、Git 服务的配置文件里的 SECRET_KEY 和 INTERNAL_TOKEN。这些得随数据目录原样迁过去(cp -a 保住属主和权限),key 一变,用户会被登出、加密过的数据直接解不开。
:latest 可能比版本 tag 还新。 :latest 经常跟着上游的 main 分支走,可能跑在最新 release 之前。直接照着 release tag 去 pin,反而可能是一次悄悄的降级。pin 之前核对一下:把正在跑的镜像的 digest 和候选 tag 的 digest 比一下,确认一致再切。
共享数据库最好拆成每个 Stack 自带。 早期常见的做法是好几个服务共用一个外部 Postgres,各自连 host.docker.internal:5432。给每个 Stack 配一个自带的 Postgres 更清爽:隔离性更好、每个应用独立的版本和备份、没有共享的单点、host 的 5432 也不用再对外发布。改动其实很小,数据库名、用户、密码全保持原样(密码存成 Komodo Variable),应用配置里只有连接的 host 从 host.docker.internal 变成自带服务的名字(比如 app-postgres)。迁数据用逻辑 dump 最稳,它跨大版本可移植:
# 从共享库里只导出这一个数据库docker exec <shared-pg> pg_dump -U postgres -Fc --no-owner --no-acl -d <db> > <db>.dump
# 用一个一次性容器初始化新数据目录并恢复,恢复完删掉容器,数据留在盘上docker run -d --name tmp-pg -e POSTGRES_USER=<u> -e POSTGRES_PASSWORD=<pw> \ -e POSTGRES_DB=<db> -v /srv/<svc>/postgres:/var/lib/postgresql postgres:18-alpine# 等就绪后 pg_restore,再 docker rm -f tmp-pg需要小工具,就起一个 sidecar。 别往应用的官方容器里手装东西,那些东西每次拉新镜像就没了。把额外逻辑挪进一个本地构建的小服务,和官方镜像并排放:
services: app: image: ghcr.io/vendor/app:v1.80.0 # 官方镜像,保持干净 app-notify: build: ./notify # 本地构建的小服务,应用通过服务名在网络内访问再给这个 Stack 加 extra_args = "--build",部署时就会 docker compose up -d --build 把 sidecar 一起构建出来。官方镜像不被污染,Renovate 还能继续 bump 它的 tag 和 sidecar Dockerfile 的 FROM。
还有几条零碎但要命的:匿名卷里也可能存着真实数据,用 docker inspect <容器> --format '{{json .Mounts}}' 把挂载全列出来,别只看 compose 文件;joined 到某个共享网络(带固定 IP)的服务迁移后得留在那个网络上;搜索引擎的索引(Elasticsearch、Meilisearch)是派生数据,迁移时可以不管,恢复后重建一遍即可;用了 network_mode: host 或 privileged 的特殊应用不套用端口和命名网络那套约定,只迁配置目录、保留它原本的网络模式和设备挂载。
切换后核对容器状态、curl 一下端口、看日志确认连上了数据库、数据还在。确认无误后,老的命名卷和 /opt/<service> 目录就是回滚后路,等放心了再清掉。
防火墙:怎么挡住公网又不会把自己锁死
很多自托管的人会把所有服务统一藏在一台反向代理后面:公网域名都解析到这台反代(下面叫它反代 B),由它统一终结 TLS,再回源到真正跑服务的应用服务器(叫它 A)。这套结构很常见,但它有一个默认状态下敞开的后门。
Docker 发布端口时,默认把端口绑在 0.0.0.0 上,并且不限制来源。也就是说,服务器 A 上 20000:80 这样的发布,让任何知道 A 公网 IP 的人都能直接打 http://A:20000,绕开反代 B 连同它的 TLS 和前置防护。要堵的就是这条直连路径:让 A 的这些端口只对反代 B 开放,另外放行少数几个确实需要面向公网的端口。
在 Docker 主机上做端口过滤有个经典陷阱,不绕开很容易把自己关在门外。Docker 发布的端口流量在内核的 prerouting 阶段就被 DNAT 改写目标地址,然后走 forward 链转发到容器,host 的 INPUT 链根本看不到它们。所以加在 INPUT 上的 drop 规则对 Docker 端口毫无作用。正确的拦截位置在 forward 路径上的 DOCKER-USER 链,这是 Docker 专门留给用户的链,它在 Docker 自己的 accept 规则之前先被求值,而且 Docker 重建规则时会保留它的内容。
顺着这条主线,有四件事要做对,规则才既有效、又不会反噬自己。
第一,过滤只动 DOCKER-USER 链,针对公网网卡。容器之间在内部桥接网络上的通信、容器对外的出站流量都不匹配「入站公网网卡」这个条件,所以内部互联和访问外网都不受影响。
第二,INPUT 策略保持 accept,host 进程的端口(SSH、反代用的 80/443)照常放行。要限制某个走 host 网络的端口,就单开一个子链、只丢弃那一个端口。这么设计的用意只有一个:就算规则写错了,也伤不到 SSH,人永远能登进来修。
第三,只用原生 iptables/ip6tables 管这一条链,别装 ufw 或 firewalld。那类工具会接管整套链和默认策略,跟 Docker 抢地盘,光一个 FORWARD 默认 DROP 就能让所有容器转发瘫掉。
第四,IPv4 和 IPv6 都要管。端口通常在两个协议栈上都发布了,如果反代 B 只有 IPv4 地址,那 IPv6 这一侧就没有可信来源,规则上只放行那几个公网例外、其余全丢,把「IPv4 配了白名单、IPv6 却敞着」这个常见漏洞堵上。
落到规则上,IPv4 的 DOCKER-USER 大致长这样:
# 作用在公网网卡 eth0 上-A DOCKER-USER -i eth0 -m conntrack --ctstate RELATED,ESTABLISHED -j RETURN-A DOCKER-USER -i eth0 -s <PROXY_B_IP> -j RETURN # 只放行反代 B-A DOCKER-USER -i eth0 -p tcp --ctorigdstport 222 -j RETURN # 比如 git over ssh,需公网-A DOCKER-USER -i eth0 -p tcp --ctorigdstport 65231 -j RETURN # 比如 BT 端口,需公网-A DOCKER-USER -i eth0 -j DROP # 其余一律丢弃DNAT 还带来一个细节:经过 DNAT 之后,普通的 --dport 看到的是容器内部端口(80、8083),原始的 host 端口(20000)已经被改写掉了。所以匹配端口例外要用 conntrack --ctorigdstport 去对 DNAT 之前的原始 host 端口;而按来源 IP(反代 B)匹配不受 DNAT 影响,照常生效。
最后一条经验比规则本身更重要:任何有风险的防火墙改动都套一个定时自动回滚。先存好当前规则,用 systemd-run 设一个十分钟后自动恢复的定时器,再应用新规则,验证没问题就取消定时器;万一把自己关在外面,什么都不用做,十分钟后规则自己滚回来。
iptables-save > /root/fw-backup.rulessystemd-run --on-active=600 --unit=fw-rollback \ /bin/sh -c 'iptables-restore < /root/fw-backup.rules'# 应用新规则、验证;没问题就:systemctl stop fw-rollback.timer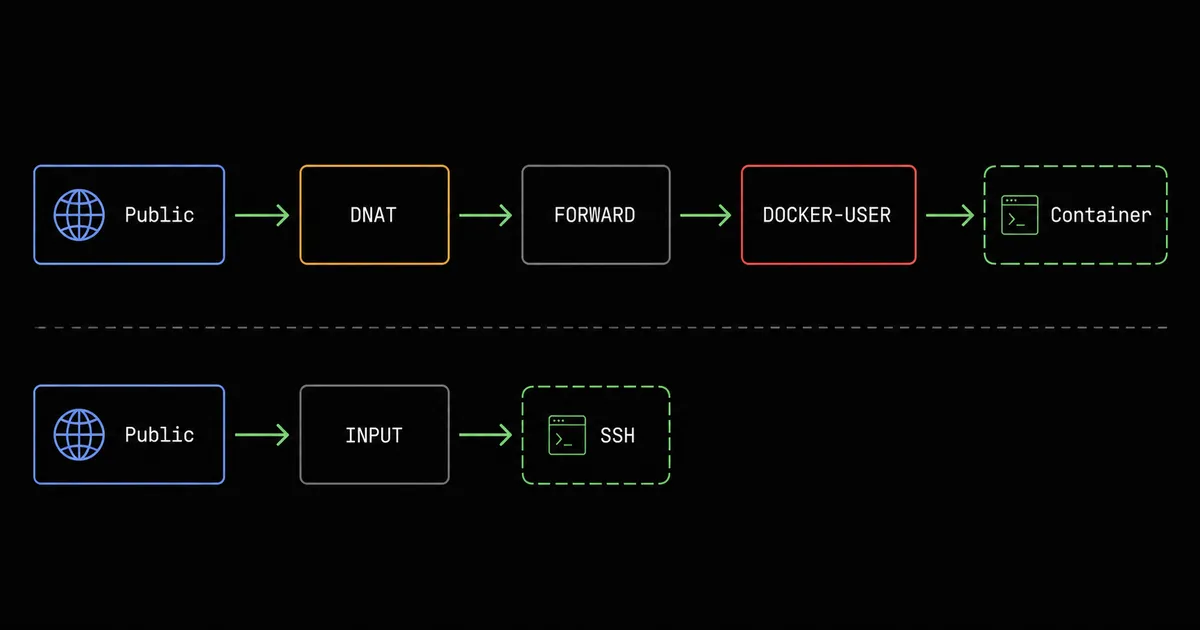
这张图画的是两条不同的包路径:Docker 发布的端口走 DNAT 加 forward,落在 DOCKER-USER 上拦截;SSH 这类 host 端口走 INPUT,始终放行。看懂它就明白 drop 规则该写在 forward 路径的 DOCKER-USER 上,因为 DNAT 之后 INPUT 已经看不到这些包。
备份:三层状态,分类控制
Git 里有全部声明,但光靠 git clone 重建不出一台服务器,因为真正的状态分散在三层,各有不同的归属和备份方式。要从彻底丢失里恢复,三层都得在手上。
| 层 | 内容 | 在哪 | 谁来备份 | 丢了会怎样 |
|---|---|---|---|---|
| 1. 代码 / IaC | compose、sync.toml、文档 | Git 仓库 | 推到远端(异地) | git clone 找回 |
| 2. 控制平面元数据 | 资源定义、变量 / 密钥、用户、API key、Git 和 registry 账号 | Komodo 的数据库 | 内置 dump(每天) | 密钥和账号全没,得手工重配 |
| 3. 应用数据 | 各服务的库、上传文件、应用自持的 key | 数据根目录 /srv |
自己安排 | 用户数据真的没了 |
为什么三层缺一不可,用一个例子就清楚:仓库定义了每个 Stack 是什么,但每一个密钥要么是 Komodo 里的变量、要么藏在 /srv 里,Git 里只有占位符。所以恢复是三件事的合体:Git 重建定义,数据库 dump 找回密钥和账号,/srv 备份找回数据。
第一层最简单,推到一个异地的 Git 远端就行,这一步多数人本来就在做。
第二层,Komodo Core 自带一个 km 命令行工具,可以把数据库各集合 dump 成 gzip 文件。把它配成一个每天定时跑的 Procedure,dump 进一个带时间戳的目录、保留最近若干份,整个过程在 UI 里可见、可告警。要当心的是,dump 里那份变量文件装着全部明文密钥,没有加密,绝不能不加密就拷下机器。
第三层最容易被忽略,得自己安排。给数据库做一致的备份靠两种安全办法:对每个 Postgres 容器跑 pg_dumpall 做逻辑 dump(跨大版本可移植),或者把 Stack 停掉做冷拷贝。直接拷一个正在跑的数据库的数据目录,可能拷到一个写到一半、还原不了的状态。一个参考脚本的骨架:
#!/usr/bin/env bashset -euo pipefaildest="/srv/_backups/$(date +%F_%H-%M-%S)"; mkdir -p "$dest/pgdump"
# 逻辑 dump 每个 Postgres 容器(官方镜像本地 socket 是 trust,无需密码)for c in $(docker ps --format '{{.Names}}'); do docker inspect "$c" --format '{{.Config.Image}}' | grep -q postgres || continue docker exec "$c" pg_dumpall -U postgres | gzip > "$dest/pgdump/$c.sql.gz"done
# 文件级快照 /srv(上传、应用配置、应用自持的密钥),排除可重建的搜索索引tar --exclude='/srv/_backups' --exclude='/srv/*/elasticsearch' \ -czf "$dest/srv.tar.gz" /srv把它配成每天定时(Komodo Action 或主机 cron),排在数据库 dump 之后,这样一次异地推送能把两份一起带走。
第三层的重点是异地。如果所有备份都躺在和数据同一块磁盘上,一次磁盘或服务器故障会把数据连着备份一起带走。业界的 3-2-1 原则是底线:3 份副本、2 种介质、1 份异地。dump 里有密钥,异地之前必须客户端加密,用 restic 或 rclone crypt 这类内置加密的工具,目标可以选任意对象存储。
恢复时按层来。回滚单个服务,就停掉它、把对应的 pg_dump 灌回去或把 /srv/<service> 解包回去(tar -p 保留属主权限),再从 UI 重新部署。整机重建则严格按「先密钥和数据、后部署」的顺序:装好 Docker,恢复 Komodo 自己的环境文件和密钥卷并把 Core 拉起来(数据库此时是空的),把数据库 dump 灌回去(变量、账号、资源定义随之回来),把 /srv 和各 pg_dump 恢复到位,最后推一次 main 让所有 Stack 在恢复好的数据上重新部署,再重建那些派生的搜索索引。
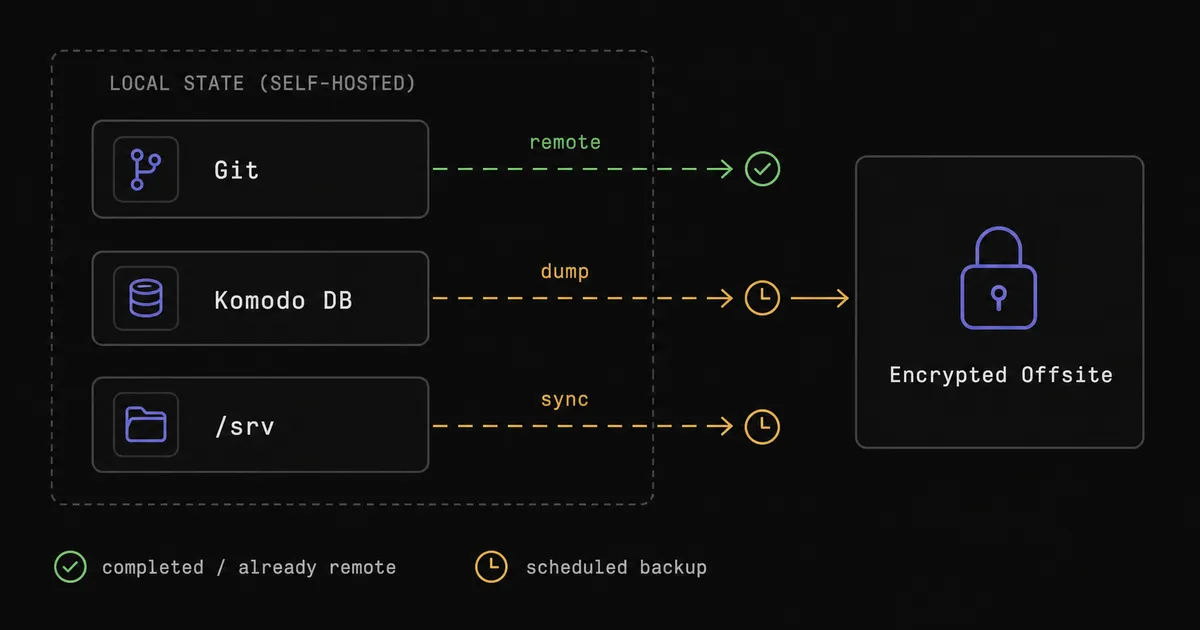
把更多服务器纳入管理
在 Komodo 的 Core/Periphery 模型架构下,添加管理更多服务器也并不困难,加一台机器的本质就是给它装上 Periphery、再连到同一个 Core。
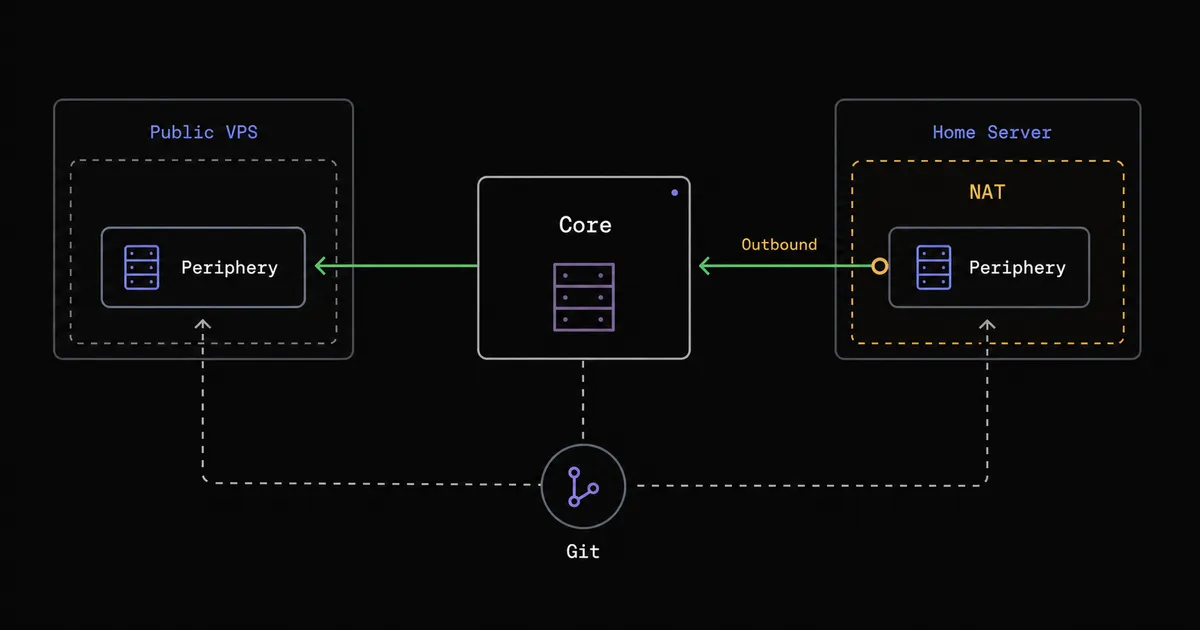
这张图画的是两种连接方向:有公网地址的机器由 Core 连进去,NAT 后的家用机自己拨出来连 Core。两种都挂在同一个 Core 下,归同一套 Git 管。
连接有两个方向,按新机器能不能被 Core 直接够到来选。
一种是 Core 主动连 Periphery。在新机器上跑 Periphery,让它监听一个端口(默认 8120),再在 Komodo 里加一个 Server 资源,地址填这台机器的地址,比如 http://server-b:8120。这适合有固定地址、Core 够得着的机器,比如另一台公网 VPS。这个 8120 端口要像别的端口一样锁好,只放行 Core 来访。
另一种是 Periphery 主动连 Core(较新版本的 outbound 模式)。Periphery 拿着一个 onboarding key 主动拨向 Core 的地址,建立一条双向 websocket。家里的机器多半在 NAT 后面、拿不到公网入口,这种主动外拨正好对症,省去在家里开端口、做端口映射的麻烦。
outbound 模式装起来就一条命令:先在 Komodo 的 Server 设置里生成一个 onboarding key,再到新机器上跑官方安装脚本。
curl -sSL https://raw.githubusercontent.com/moghtech/komodo/main/scripts/setup-periphery.py \ | python3 - \ --core-address="https://<Core 地址>" \ --connect-as="$(hostname)" \ --onboarding-key="O-..."安装脚本执行好后,这台机器便以 connect-as 给的名称出现在 Komodo 的 Servers 列表里。
GitOps 那套原样套上去就行。既然「有哪些服务」能写进 sync.toml,「有哪些服务器」同样可以,加一个 [[server]] 块,连服务器清单本身都变成代码:
[[server]]name = "server-b"description = "家里的存储机"tags = ["home"]
[server.config]address = "http://localhost:8120"enabled = true要把某个服务跑到这台新机器上,只改它 [[stack]] 块里的一行:
[stack.config]server = "server-b" # 从 server-a 改成新机器run_directory = "stacks/<service>"file_paths = ["compose.yaml"]推送之后,那条 Redeploy On Push Procedure 一视同仁地把变更过的 Stack 部署到它各自声明的服务器上。一个仓库、一套 Renovate、一条流水线,现在横跨好几台机器;一个面板里就能看到所有机器的所有服务,升级 PR 也覆盖全部。
多机之后有几件事要分开算。每台机器有自己的 /srv 数据根目录,备份也各做各的,那套三层备份在每台机器上各跑一份。端口登记表可以继续用一张全局表,也可以每台一张,端口只在同一台机器内才会撞。跨机器通信走网络地址:Docker 的桥接网只在单机内部有效,一台机器上的服务要访问另一台上的,得通过公网地址,或者用一层内网穿透(比如 Tailscale 这类 mesh)把它们接进同一个虚拟网段。
最终是一套各司其职的小集群:对外的归公网 VPS,消耗存储的由家里的 homelab 负责,全部收敛于同一个 Git 仓库、同一个面板下。
这套做法适合谁,怎么开始
最适合的场景是:一两台长期跑、服务数量在十个以上、又希望升级和回滚都留痕的自托管环境。服务再少,手动管的心智负担本来就低,上这套略显重;真到几十上百台、多人协作的规模,该看的是 Flux、Argo CD 这类 Kubernetes 原生的 GitOps 工具。Komodo 加 Renovate 这套正好接住中间这段,比纯手工可靠得多,又比 Kubernetes 轻得多,对个人和小团队的自托管刚刚好。
实际搭建,按这个顺序起步最顺。先在一台主机上手动拉起 Komodo(Core、Periphery、数据库),这是唯一一处手动操作。建一个 Git 仓库,放一个最简单的服务,照 wallos 那个例子写好 compose.yaml,把数据 bind 到 /srv、端口登记进一张表。在 Komodo UI 里配好指向仓库的 Repo 资源和相关变量,写一个 sync.toml 把这个 Stack 声明出来、全部设 deploy = false。再建一个两段式的 Redeploy On Push Procedure(先 RunSync、后 BatchDeployStackIfChanged),把它的 push webhook 挂到仓库上。最后装上 Renovate,合并那个引导 PR。
跑通这一个服务之后,加第二个、第三个就只是重复同样的四步:写 compose、加 sync 条目、认领端口、推送。此后改动都走 Git、Renovate 提 PR、人工审核合并,服务器自己跟上,整台机器的状态再也不会散落在 Git 之外。
参考链接
- Komodo 官方文档,Core/Periphery 架构、Stack、Resource Sync、Procedure、Webhook 的相关说明
- Komodo Resource Sync 文档,用 TOML 声明资源
- Renovate 官方文档,docker-compose manager、packageRules、调度与分组
- OpenGitOps 原则(CNCF),GitOps 四原则的权威定义
- Docker Compose 环境变量与插值官方文档,
environment、env_file与.env的区别 - How to automate version updates for self-hosted Docker containers with Gitea, Renovate and Komodo,同一套链路的相关教程
- Migrating to Komodo(foxxmd),从其他工具迁移到 Komodo
- Komodo Tips and Tricks(foxxmd),Komodo 的实用技巧
- Scaling Renovate(foxxmd),多仓库、多服务下如何压住 PR 噪音
- Docker Compose Envs Explained(foxxmd),环境变量
- Komodo: a better alternative to Portainer(skyblog),Komodo 的定位与使用